
Advanced Topics of Measurement and Evaluation
If you want to build your career around measurement and evaluation, you may need to know what topics are considered important. The following is a list of topics classified by Measurement and Evaluation Program Committee of American Educational Research Association (AERA). The explanation of each topic is added by myself and does not represent the official definition of AERA.
Even if you do not plan to be a statistician, knowledge of measurement and evaluation is essential to educational researchers in general. Although opinion-papers or theoretical papers are acceptable by some professional conferences and referred journals, empirical substantiation is still preferable. When an educational researcher wants to test an educational theory or an instructional product, it is inevitable to get involved with measurement and evaluation. It is a "necessary evil"!
It is impossible for you to become an expert on every topic. Life is short! Nonetheless, a basic understanding of all following terms are recommended. After acquiring the overall structure, you may consider to specialize in one or several areas.
Measurement
- Validation
Validation is process to establish the content validity, criterion validity, or/and construct validity of a test (American Psychological Association, 1985). For a summary of validity, please read the lesson Reliability and Validity.
- Computer Adaptive Testing
A Computer Adaptive Test (CAT) is a test customized by a computer system based upon the responses of the tester (Wainer, 1990). For instance, if a tester scores perfectly in the first fifteen questions, the computer system may skip all the rest of remaining questions. But if a tester gives incorrect answers to certain questions, different questions relating to the same topics may pop up again.
- Classical Test Theory
Classical test theory is based upon the True Score Model introduced by Spearman. It is hypothesized that an observed score is composed of a true score and an error score. A true score reflects the tester's actual ability while an error score is resulted from chance fluctuations (Crocker & Algina, 1986; Pedhazur & Schmelkin, 1991).
- Item Response Theory
Item Response Theory (IRT) is also known as Latent Trait Theory because it assumes that the responses to test items can be accounted for by latent traits that are fewer in number than the test items (Hulin, Drasgow, & Parsons, 1983).
- Scaling, Equating
Scaling is a study of developing systematic rules and meaningful units of measurement for quantifying psychological constructs and empirical observations. A typical example is to assign IQ to measure intelligence. Equating is a study of establishing equivalent scores of two tests. A typical example is equating paper-and-pencil tests with computer adaptive tests (CAT) (Crocker & Algina, 1986; Kolen, & Brennan, 1995).
- Criterion Reference Testing
A test that yields the information of a student's skill level according to the criteria of the subject matter is called criterion reference testing (Kubiszyn, & Borich, 1993).
- Norm Reference Testing
A test comparing the student's performance to a norm or average of performances by other, similar students is called a norm reference test (Kubiszyn, & Borich, 1993). Typical examples are standardized tests such as GRE and SAT.
- Cognitive psychology
Cognitive psychology is a study of human mental processes and their role in thinking, feeling, and behaving (Kellogg, 1995). Cognitive psychology is helpful to educational psychologists in developing mental constructs relating to learning such as short term memory, long term memory, procedural knowledge, declarative knowledge, problem solving, logical reasoning...etc (Anderson, 1990). These mental constructs are commonly used in evaluation of treatment effectiveness. You may read my write-up What is Intelligence? to learn about two major cognitive models.
- DIF, Item Bias Approaches
In a test, subgroups of testers often have very different distributions of proficiencies. Differential Item Functioning (DIF) is a procedure to identify test items that operate differentially for different subgroups conditional on the proficiency of test-takers. The aim of DIF is to reduce or eliminate test item bias (Holland & Wainer, 1992).
- Test Bias
It is a study of statistical procedures to examine systematic errors of standard tests. When certain categories of testers such as females and ethnic minorities receive lower than average scores due to systematic errors of a test, this test are considered biased and violates construct validity. Besides DIF, other statistical procedures for discovering/reducing test bias are Transformed Item Difficulties, Chi Square, and Distractor Response Analysis. (Osterlind, 1983).
- Large-Scale Testing Programs
Statistics
- Bayesian
Traditional statistical inference leads to an "either-or" conclusion-to reject the null hypothesis or fail to reject the null hypothesis. Bayesian approach views scientific reasoning in probabilistic terms. When evaluating an uncertain claim, one does so by calculating the probability of the claim in the light of given information (Howson & Urbach, 1993).
- Structural Equations
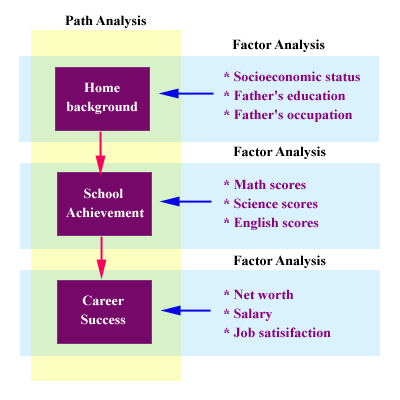
Stuctural Equation Modeling (SEM) is a statistical procedure to determine causation among variables by combining factor analysis and path analysis. It is also known as LISREL because SEM is commonly computed by LISREL, a module in the software Statistics Programming for Social Scientists (SPSS) (Pedhazur & Schmelkin, 1991). In factor analysis we collapse many measurement items as a few factors whereas in path analysis we determine the path of cause and effect relationship among variables (Lomax, 1992) (see the following figure).
- Power Analyses/Effect Sizes
Power analysis is a procedure to determine how big the sample size should be in order to enhance the probability of reject the null hypothesis correctly (Cohen, 1988) Power is a function of sample size, alpha level, and effect size. The latter is a concept of meta-analysis, an analysis of previous research analyses for concluding the overall effect of a particular treatment method (Glass, McGraw, & Smith, 1981). You may see a QuickTime illustration of the relationship among power, effect size, and sample size. The QuickTime illustration requires a sound card and a larger screen. When the page is open, double click on the screen to start the illustration.
- Log Linear Models
Log Linear model is a type of categorical data analysis for handing multiway contingency tables (Stevens, 1992).
- HLM
When a variable is a sub-category of another variable, the former is considered being "nested" with the latter and their relationship is termed as hierarchical. Hierarchical Linear Modeling (HLM) is the analysis of models with two or three levels of nesting (i.e., multilevel analysis). Such nested models may be used to analyze growth and change within individuals.
Research Design/Evaluation Methods
- Qualitative Approaches
- Evaluation Methods
- Mixed Methods
- Quantitative Approaches
- Life History
- Historical Approaches
- Narrative Approaches
- Critical Orientations (Feminism, Postmodern)
References
American Psychological Association. (1985). Standards for Educational and Psychological Measurement. Washington D.C.: Author.
Anderson, J. R. (1990). Cognitive psychology and its implications. New York : W.H. Freeman.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences. Hillsdale, N.J. : L. Erlbaum Associates.
Crocker, L. & Algina, J. (1986). Introduction to classical and modern test theory. Forth Worth, TX: Harcourt Brace Jovanovich College Publishers.
Glass, G. V., McGraw, B., & Smith, M. L. (1981). Meta-analysis in social research. Beverly Hills, Calif. : Sage Publications.
Holland, P. W., & Wainer, H. (Eds.). (1992). Differential item functioning : Theory and practice. Hillsdale : Lawrence Erlbaum Associates, 1992.
Howson, C. & Urbach, P. (1993). Scientific reasoning: The Bayesian approach. Chicago, IL: Open Court.
Kellogg, R. T. (1995). Cognitive psychology. Thousand Oaks: sage Publications.
Kolen, M. J. & Brennan, R. J. (1995). Test Equating: Methods and Practices. New York: Springer.
Kubiszyn, T. & Borich, G. (1993). Educational testing and measurement: Classroom application and practice. New York: Harper Collins College Publishers.
Lomax, R. G. (1992). Statistical concepts: A second course for education and the behavioral sciences. White Plains, NY: Longman.
Osterlind, S. (1983). Test item bias. Newbury Park: Sage Publications.
Pedhzzur, E. J. & Schmelkin, L. P. (1991). Measurement, design, and analysis: An integrated approach. Hillsdale, NJ: Lawrence Erlbaum Associates, Publishers.
Stevens, J. (1992). Applied multivariate statistics for the social sciences. Hillsdale, NJ: Lawrence Erlbaum Associates, Publishers.
Hulin, C. L., Drasgow, F., & Parsons, C. K. (1983). Item response theory : Application to psychological measurement. Homewood, Ill. : Dow Jones-Irwin.
Wainer H. (1990). Introduction and history. In Wainer H (Ed.), Computer adaptive testing: A primer. Hilldale, NJ: Lawurence Erlbaum.
Navigation
Index
Simplified Navigation
Table of Contents
Search Engine
Contact