Structural equation model
Structural Equation Model
 n this
course it was mentioned twice that researchers should not design a
complex experiment with too many variables when the knowledge of the
subject matter is not well-understood. Nevertheless, a good architect
should build a house rather than just making bricks. As the knowledge
of the field accumulates to a degree that a synthesis is needed,
researchers should put many variables together to build a coherent
model, which specifies causal-effect relationships among those
variables. n this
course it was mentioned twice that researchers should not design a
complex experiment with too many variables when the knowledge of the
subject matter is not well-understood. Nevertheless, a good architect
should build a house rather than just making bricks. As the knowledge
of the field accumulates to a degree that a synthesis is needed,
researchers should put many variables together to build a coherent
model, which specifies causal-effect relationships among those
variables.
 The importance of model building can be best illustrated by the
Keynesian model. What? An economic model? Yes, you are not in the wrong
class. Let me explain it. The Keynesian model was introduced by John
Maynard Keynes, the most well-known British economist in the 20th
century. This model hypothesizes how government spending can trigger
more spending in other economic sectors. This idea, "multiplier,"
originated from another economist instead of John Keynes. But that
economist is virtually unknown while John Keynes has gained world-wide
reputation. It is because instead of introducing a piece of concept,
John Keynes built a comprehensive model for explaining the
relationships among government expenditures, employment, money supply,
inflation, interest rate, investment, and gross domestic product.
The importance of model building can be best illustrated by the
Keynesian model. What? An economic model? Yes, you are not in the wrong
class. Let me explain it. The Keynesian model was introduced by John
Maynard Keynes, the most well-known British economist in the 20th
century. This model hypothesizes how government spending can trigger
more spending in other economic sectors. This idea, "multiplier,"
originated from another economist instead of John Keynes. But that
economist is virtually unknown while John Keynes has gained world-wide
reputation. It is because instead of introducing a piece of concept,
John Keynes built a comprehensive model for explaining the
relationships among government expenditures, employment, money supply,
inflation, interest rate, investment, and gross domestic product.
While dealing with many sets of variables and
relationships, inexperienced researchers may perform several separate
ANOVA and regression analyses. Indeed, a structural equation model
(SEM) should be developed to avoid "missing links" among variables. SEM
is built upon a measurement model and a structural model.
Measurement model
A measurement model, as its name implies, is about measurement and data
collection. In the section concerning reliability and Cronbach Alpha,
we discussed how researchers develop instrument with high reliability
and low measurement error. In factor analysis, researchers extract
latent variables from observed variables. The relationships are
indicated in the following figure. The ellipse represents a latent
variable such as a mental construct, the rectangles represent observed
variables, which are items in a scale. The circles denote measurement
errors.

Structural model
A structural model specifies how well some variables could predict some
other variables. Because prediction involves relationships, it could be
viewed as a regression model. Also, since the relationships form a "chain" or a "path," it is also known as path model.
When two models are combined, they form a structural equation model.
The following is an example given by Lomax (1992). Assume that based
upon literature research, a researcher hypothesizes that "home
background" could be a predictor to "school achievement," and "school
achievement" could predict "career success", he should define such
vague concepts as home background, school achievement, and career
success. The next logical step he should go is to develop instrument
and data collection schemes to measure those latent constructs.
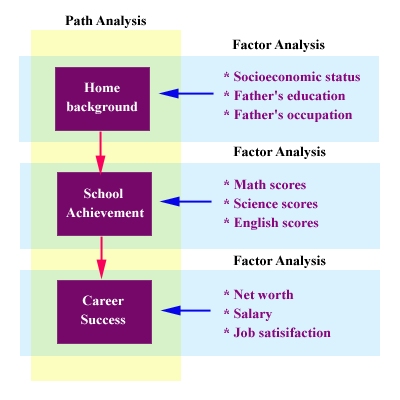
This example is simplified. A real-life structural equation model is
more complicated than that. In addition, this is an example of a
formative model (Roberts & Thatcher 2009), in which several
indicators are combined to form a socially generated construct i.e.
"Household background" or "socio-economic status" (SES) does not exist
independently. Thus, in the diagram the arrows point to the construct,
not the other way around. However, in psychology usually it is
opposite: the arrows point from the construct to the indicators. For
example, the latent construct "anxiety" exists in our cognitive
structure and this mental state drives our behaviors, as measured by
the indicators. This type of model is known as the reflective model
(Coltman, Devinney, Midgley, & Venaik, 2008).
While applying an input-output model to research on
Web-based instruction, researchers may find only one dependent variable
and independent variable, namely, test performance and the treatment.
However, while applying the input-process-output structural framework, between the input and output are involved many other observed and latent variables.
AMOS
There are many software packages for SEM. LISREL, marketed
by SPSS Inc., is used to be the most recommended program, but SPSS has
replaced LISREL with AMOS 2020). Many SEM programs require a strong
background in matrix algebra and programming skills. On the contrary,
AMOS is GUI-based. You can literally draw a model on the program
canvas, enter the data, and then test the model. Please use the
navigation buttons below the figure to walk through the simulated
modeling building process.
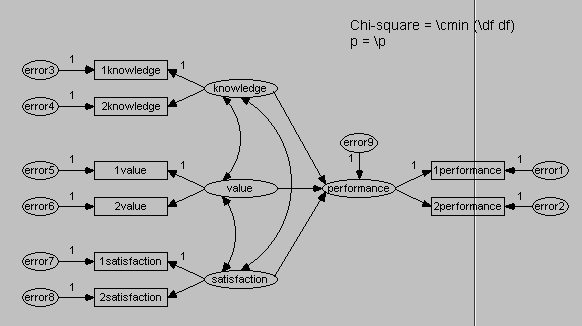
Know exactly what you're doing
The model shown in the above example contains sets of relationships.
How could that researcher formulate those relationships? Not by taking
drugs, of course. In structural equation modeling, you have to know
exactly what you are doing by drawing prior knowledge from past
research. In the measurement model for SEM, the factor analysis
employed should be confirmatory factor analysis
rather than exploratory factor analysis. American Psychological
Association (1996) pointed out the danger of treating exploratory
research as confirmatory research:
The premature formulation of theoretical models has often led to the
worst problems seen in the use of null hypothesis testing, such as
misrepresentation of exploratory results as confirmatory studies, or
poor design of confirmatory studies in the absence of necessary
exploratory results. We propose that the field become more open to well
formulated and well conducted exploratory studies with the appropriate
quantitative treatment of their results, thereby enhancing the quality
and utility of future theory generation and assessment.
Further Reading
You should be familiar with measurement theories and factor analysis
before you study structural equation model. For an overview of
structural equation model, please read Schumacker and Lomax (1996). You
can pay less attention to examples of programming syntax because
software applications for SEM is changing.
For an indepth examination of SEM, please consult Hoyle (1995).
Last update: 2021
Reference
- American Psychological Association. (1996). Task force on statistical inference initial report. http://www.apa.org/science/tfsi.html
- Coltman, T., Devinney, T. M., Midgley, D. F., & Venaik,
S. (2008). Formative versus reflective measurement models: Two
applications of formative measurement. Journal of Business Research, 61(12), 1250-1262. https://doi.org/10.1016/j.jbusres.2008.01.013
- Hoyle, R. H. (Ed.) (1995). Structural equation modeling: Concepts, issues, and applications. Thousand Oaks: Sage Publications.
- Roberts, N., & Thatcher, J. (2009). Conceptualizing and testing formative constructs: Tutorial and annotated example. ACM SIGMIS Database: the DATABASE for Advances in Information Systems, 40(3), 9-39. https://doi.org/10.1145/1592401.1592405
- Schumacker, R. E. & Lomax, R. G. (1996). A beginner's guide to structural equation modeling. Mahwah, NJ: Lawrence Erlbaum Associates.
- SPSS, Inc. (2020). AMOS http://www.spss.com/software/spss/base/Amos/overview.htm
 Go up to the main menu Go up to the main menu
|
|
